Release Notes - v12.10.0
Highlights
- Module Upload - Upload custom modules via the Administrator interface
- New QnA Interface - Brand new interface for the QnA module
- Enterprise Branding - Easier configuration to white-label Botpress
- Faster NLU Training - New way to treat out of scope data
- Broadcast Module - ** Experimental
Module Upload
Modules gives a lot of freedom to customize Botpress and add features, however it's a bit complicated to manage and update them. This release adds a new button on the Modules management page (only accessible to Super Admins), to upload module archive on the server.
Upon server restart, custom modules are loaded in priority (before built-in modules) so you can easily replace any module.
This also work if you are running Botpress on a cluster.
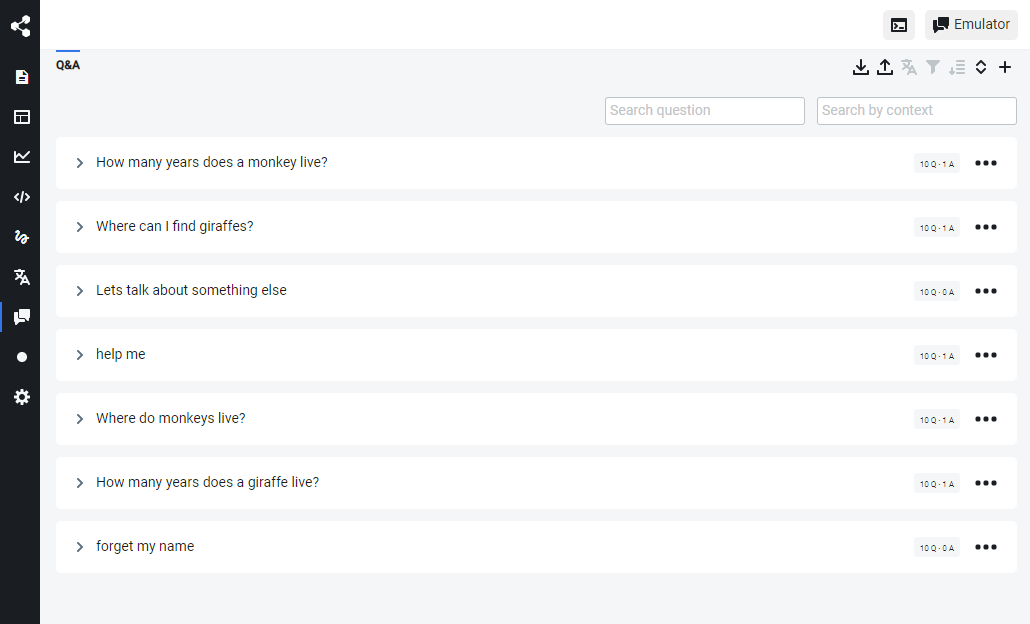
New QnA Interface
We are working on a brand new interface for the Studio and we decided to rewrite the QnA module interface from the ground up. We are removing most modals to make building with Botpress more productive.
Enterprise Branding
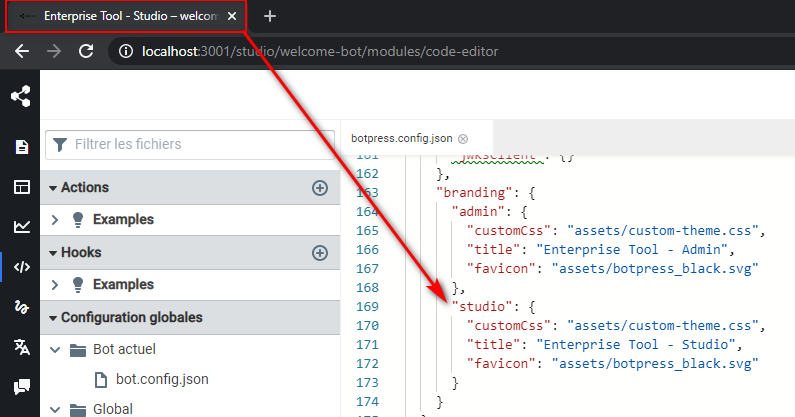
This release makes it easier for enterprises to white-label Botpress. Previously, the Admin and the Studio tried to load the file custom-theme.css, which would complement the existing stylesheet on these interfaces. That mechanism has been slightly modified.
In order to use a custom stylesheet, change the software title or use a custom favicon, you must have an enterprise license. Then, head over to the botpress.config.json file, and edit the keys under pro.branding
There is more information on GitHub - White Label Example
Broadcast Module
This is the first step in bringing back the Broadcast module from Botpress 10, but it is still a work in progress and it is not recommended to use it in production. We are marking it as "Experimental" for the time being.
Faster NLU Training
Prior to 12.10, out of scope model was trained on the whole chatbot data not taking context into account which not only was much longer and harder to train but also less accurate. With this upgrade, Botpress now has one smaller out of scope model per context making training faster and more accurate. Moreover, this small change makes the whole training pipeline cacheable which will end up in huge gains in a near future.